
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
KSC, 2023
KSC, 2023
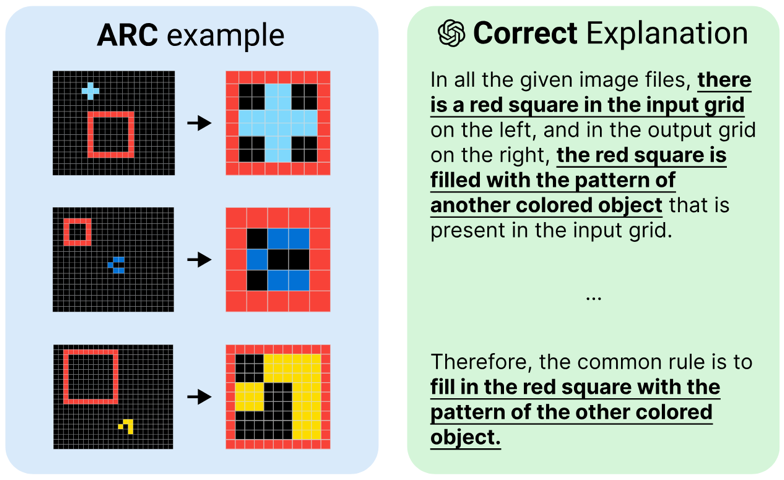
Donghyeon Shin*, Seungpil Lee*, Klea Lena Kovacec, and Sundong Kim†
In IJCAI Workshop on Analogical Abstraction in Cognition, Perception, and Language, 2024

Hosung Lee*, Sejin Kim*, Seungpil Lee, Sanha Hwang, Jihwan Lee, Byung-Jun Lee†, and Sundong Kim†
In CoLLAs, 2024
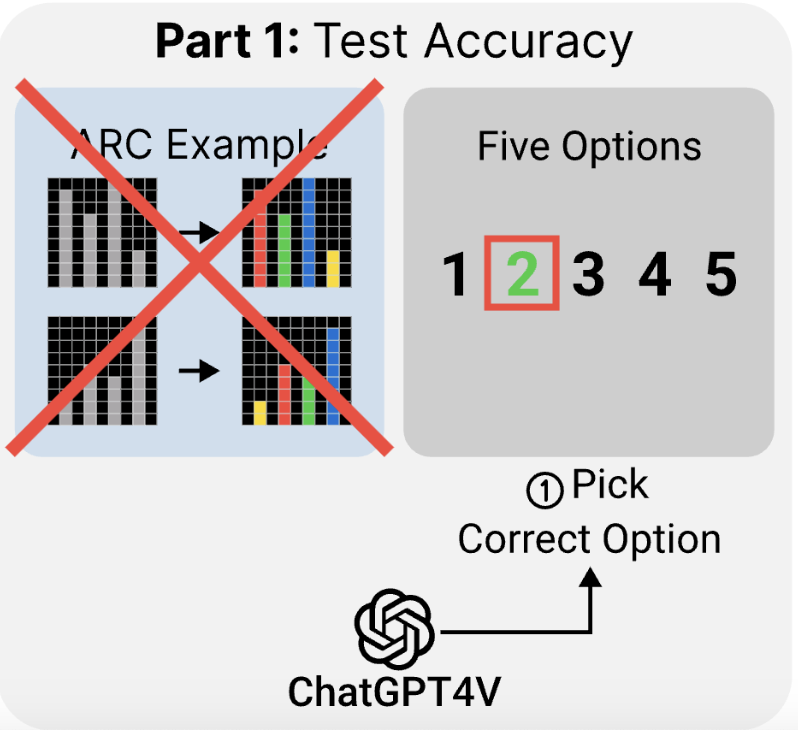
Donghyeon Shin*, Seungpil Lee*, Klea Lena Kovacec, and Sundong Kim†
In EMNLP Findings, 2024
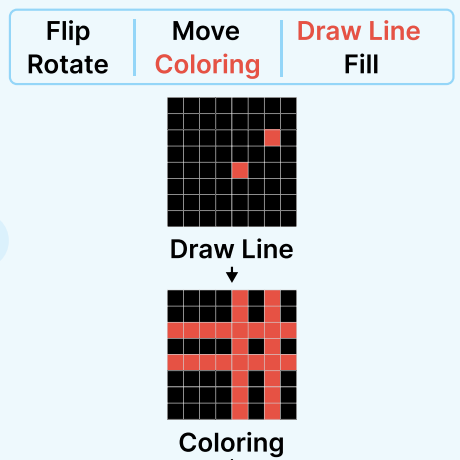
Seungpil Lee*, Woochang Sim*, Donghyeon Shin*, Sejin Kim and Sundong Kim†
In NeurIPS Workshop on System-2 Reasoning at Scale, 2025
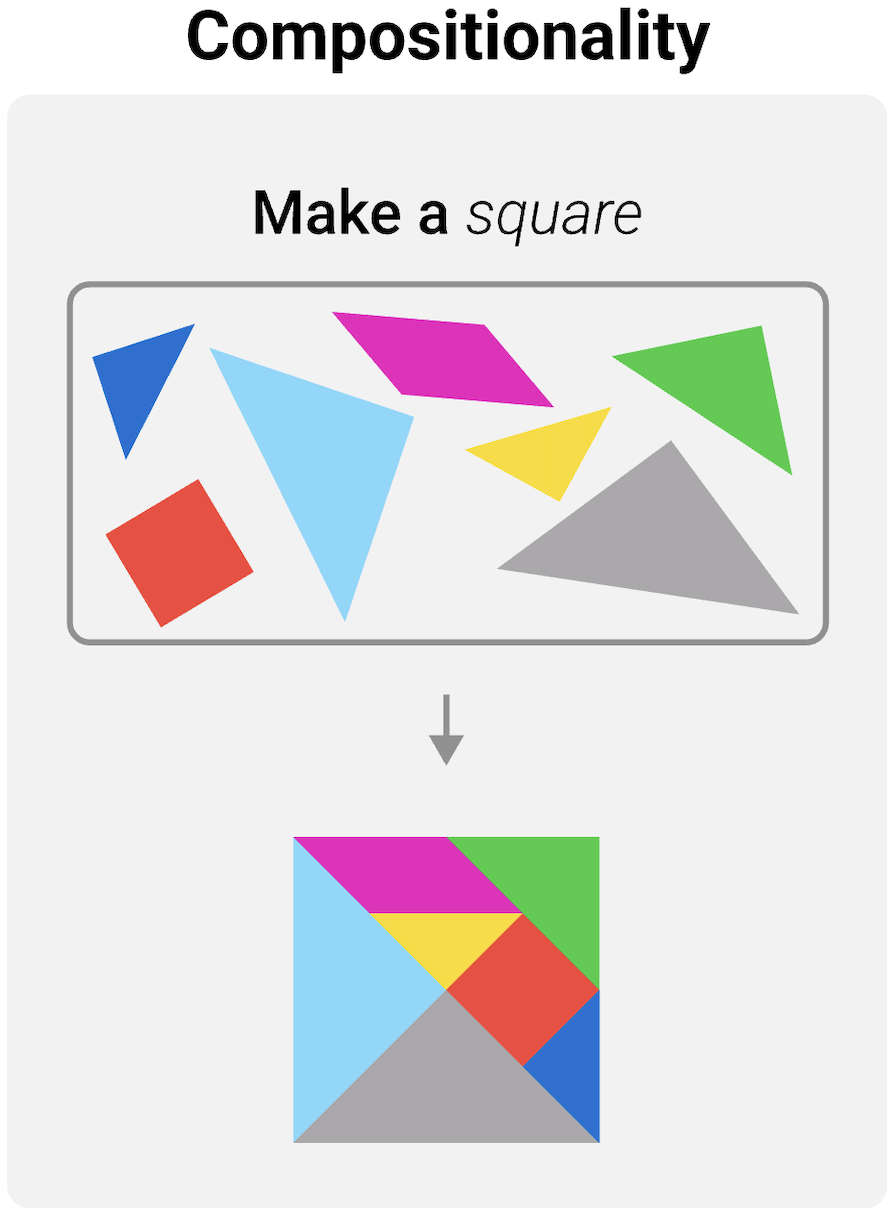
Seungpil Lee*, Woochang Sim*, Donghyeon Shin*, Wongyu Seo, Jiwon Park, Seokki Lee, Sanha Hwang, Sejin Kim and Sundong Kim†
ACM Transactions on Intelligent Systems and Technology (Accept with Minor Revision), 2025
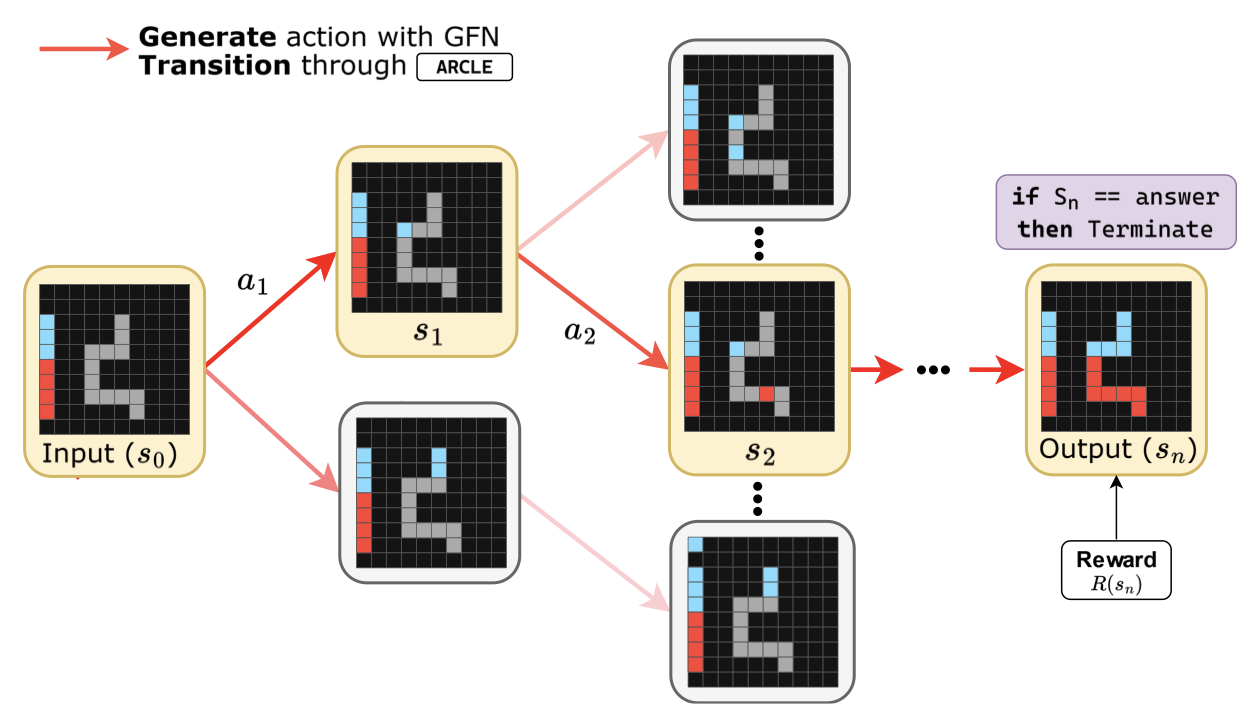
Sanha Hwang, Seungpil Lee, Sejin Kim, and Sundong Kim†
Transactions on Machine Learning Research, 2025
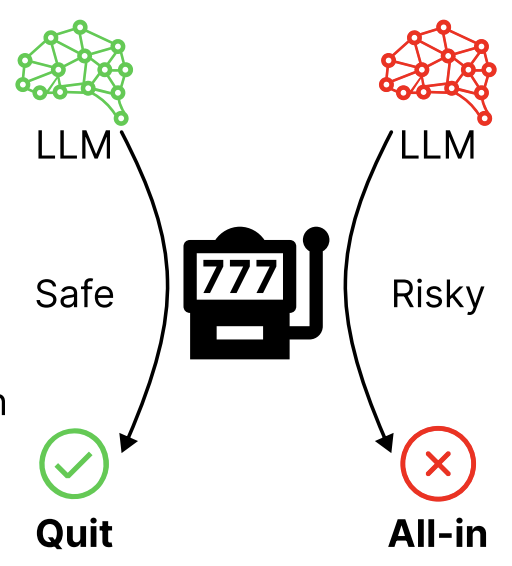
Seungpil Lee*, Donghyeon Shin, Yunjeong Lee and Sundong Kim†
arXiv preprint, 2025
Posts
publications
KSC, 2023
KSC, 2023
Hosung Lee*, Sejin Kim*, Seungpil Lee, Sanha Hwang, Jihwan Lee, Byung-Jun Lee†, and Sundong Kim†
In CoLLAs, 2024
Donghyeon Shin*, Seungpil Lee*, Klea Lena Kovacec, and Sundong Kim†
In IJCAI Workshop on Analogical Abstraction in Cognition, Perception, and Language, 2024
Donghyeon Shin*, Seungpil Lee*, Klea Lena Kovacec, and Sundong Kim†
In EMNLP Findings, 2024
Seungpil Lee*, Woochang Sim*, Donghyeon Shin*, Sejin Kim and Sundong Kim†
In NeurIPS Workshop on System-2 Reasoning at Scale, 2025
Seungpil Lee*, Woochang Sim*, Donghyeon Shin*, Wongyu Seo, Jiwon Park, Seokki Lee, Sanha Hwang, Sejin Kim and Sundong Kim†
ACM Transactions on Intelligent Systems and Technology (Accept with Minor Revision), 2025
Sanha Hwang, Seungpil Lee, Sejin Kim, and Sundong Kim†
Transactions on Machine Learning Research, 2025
Seungpil Lee*, Donghyeon Shin, Yunjeong Lee and Sundong Kim†
arXiv preprint, 2025