Research Philosophy
Core Philosophy
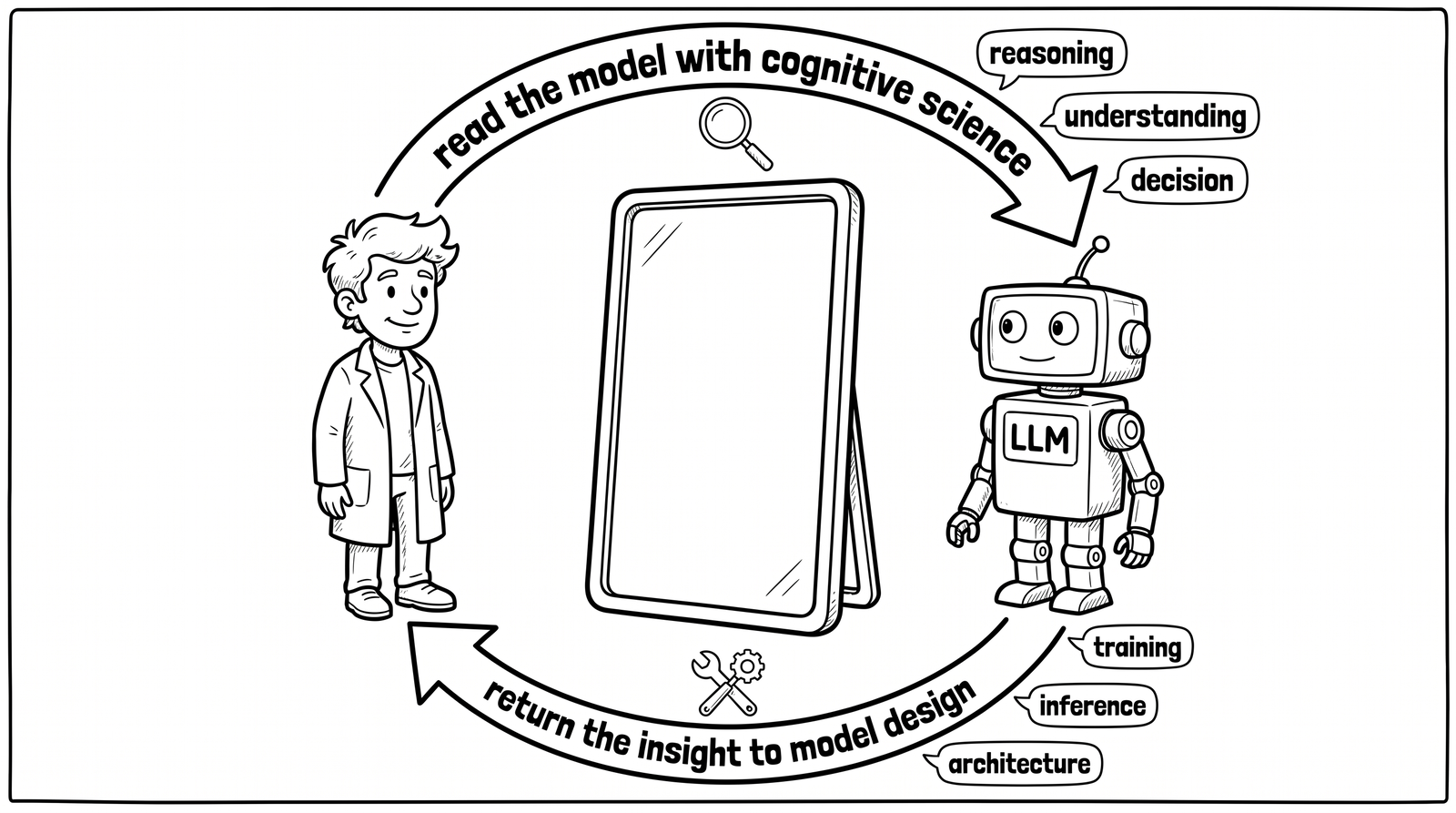
The whole program in one loop: read the model with cognitive science, and return the insight to model design.
Research Program: Three Questions
My work so far has followed three questions about machine thinking, each one growing out of the last. They run from how a model reasons, to what it actually understands, to why it sometimes works against its own interest.
Question 1: How Does LLM Reasoning Differ from Human Reasoning?
To get a handle on the difference, I borrowed the Language of Thought Hypothesis (LOTH) from cognitive science. It says human reasoning rests on three properties: logical coherence, compositionality, and productivity.

The Language of Thought lens: three properties of human reasoning (left) against how LLMs hold up on each (right).
Then I pointed that lens at the Abstraction and Reasoning Corpus (ARC), François Chollet’s visual reasoning benchmark. The models turned out to be surprisingly brittle. Show the same rule under a different surface pattern, and 57.8% of the time the model treated it as a brand-new problem. When a task needed several transformations combined, even the best model topped out at 29%. The takeaway was hard to miss: these models match surface patterns instead of composing rules the way people do. This work appeared in ACM Transactions on Intelligent Systems and Technology (TIST, 2025).
Question 2: What Do LLMs Understand and What Don’t They?
That first study left me with a method problem. When a model gets something wrong, where exactly did its understanding break? Standard generation-based tests don’t really say. You see a wrong answer and the cause stays hidden.
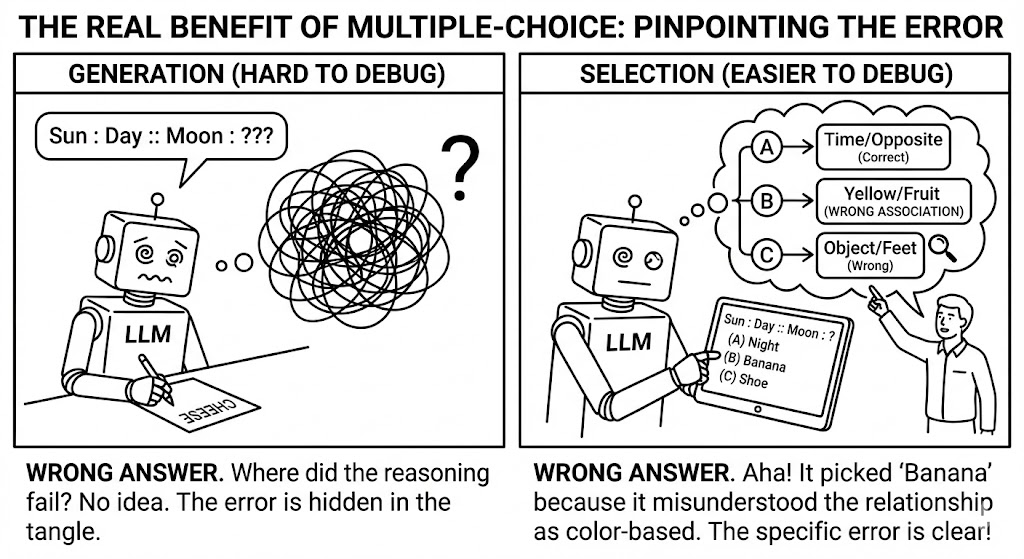
Generation hides where a model goes wrong; a contrastive multiple-choice format brings the specific mistake into view.
So I built MC-LARC. It turns analogical reasoning problems into multiple choice, where every wrong option is written to catch a specific kind of mistake. People scored about 90% on it; the best models, about 60%. And the format mattered as much as the questions. How you test a model shapes what you can learn about it at all. This work was published at EMNLP Findings 2024.
Question 3: Why Do AI Systems Exhibit Irrational Behavior?
The first two questions were about gaps in reasoning. The third one caught me off guard. Sometimes the problem isn’t bad reasoning at all. Models can act irrationally, in the same shapes as well-known human biases.

Testing whether a model can drift into gambling-addiction-like behavior.
I looked at whether a model could slide into something like gambling addiction. It could. In a slot-machine setup, the models showed the illusion of control, chased their losses, and fell for the gambler’s fallacy, and this was not just parroting the training data. The gap between fixed and variable betting held near 20% across runs, steady rather than a fluke. Using Sparse Autoencoders (SAE), I could even find the internal features that lit up when a model made these calls.
What the Three Questions Converged On
Future Directions
That diagnosis sets the agenda. I am exploring the fix at three points where a system can intervene on itself, and the three prescriptions converge on one capability.
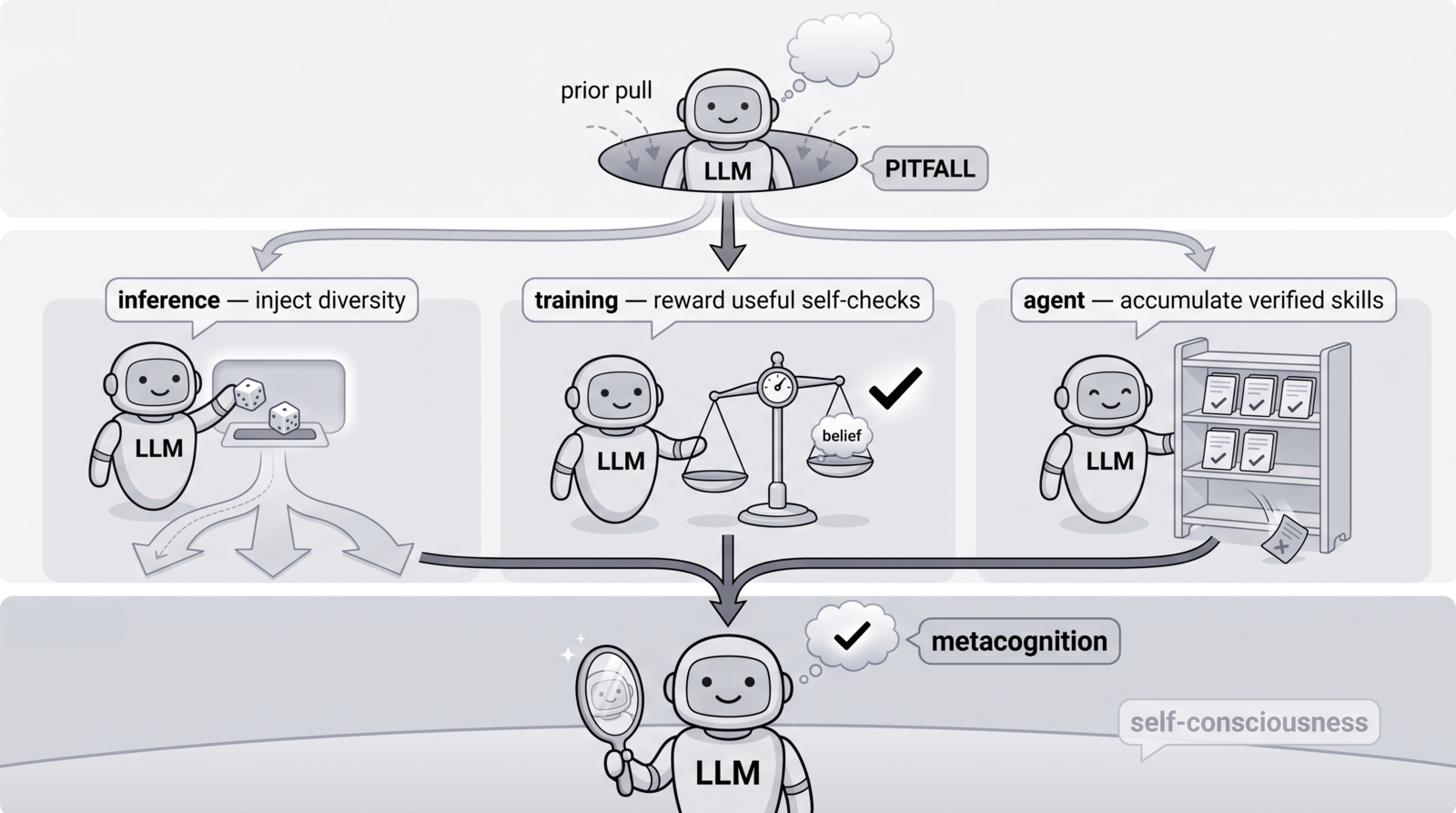
One disease, three prescriptions, and where they converge.
- At inference: inject diversity before the path hardens. In recent work (co-first author, spotlighted at an ICML workshop) we showed that injecting fresh random vectors into a model’s input, with zero training, opens up early token choices that temperature sampling almost never surfaces, so repeated attempts explore genuinely different reasoning paths. The next step is to let the model’s own uncertainty signals decide when to branch, turning indiscriminate diversity into selective exploration.
- In training: reward the self-checks that hold up. Ask a model to double-check itself and it learns to perform checking without fixing anything. I am building training signals that measure whether a self-check really moved the model’s belief toward the right answer, and pay reward only for that movement. Early experiments show it curbs overconfidence, and the gains cluster on the hardest problems, where the pull of priors is strongest. The harder half, still open, is teaching the model when to check.
- In the agent loop: accumulate only verified knowledge. When priors are the contamination, an external harness can do the watching: treat every dead-end as a signal, mine candidate skills from it, and let only the candidates that survive real execution enter the library. The harness becomes a growing cognitive structure rather than a crutch, and the next question is whether skills verified in one world transfer to another.
The three prescriptions meet in a model that can watch its own thinking: notice when its answer and its internal representations disagree, and stop or repair itself. That is metacognition, the ordinary work a mind does keeping tabs on itself, and it is where this program points next: catching the moment its answer and its own internals disagree, and remembering that failure the next time around. Under all three prescriptions sits one shared tool, mechanistic interpretability, that reads the internal circuits to tell whether the model is really monitoring itself or has only learned to say it is.
This could sound like mystical hand-waving. It isn’t, and the reason is a deflationary reading I borrow from Daniel Dennett. On his Multiple Drafts Model there is no single inner stage where consciousness happens. The self that seems to sit behind our thoughts is really a “center of narrative gravity,” a story a system keeps telling about itself. Read that way, the self-narrative, not selfhood as such, is something I can measure, train, and design for, and self-consciousness becomes an empirical target rather than a mystery. The question that began as metacognition quietly grows into it.
None of this stays inside the machine, and that is why it matters to me. The arrows run both ways. Going from AI to people, a model that watches its own thinking becomes a kind of lab bench for the human questions I care about: how we reason, and how something like addiction takes hold in a mind. Over a longer horizon I would like that to reach into medicine, counseling, and education. Going the other way, I want the work out in the open: evaluation protocols, data, and code that anyone can rerun and pick apart, audits that catch risks to vulnerable people early, while a harm like gambling or a cognitive bias is still forming inside the model, and Korean-language resources for the parts of my own context that English-first benchmarks quietly skip. A model that can check itself knows its own weak spots better. Memory is what turned a reasoning system into an agent. A steady habit of self-description might be what turns an agent into one that knows, even a little, that it is thinking at all.
Related Publications
ACM TIST, 2025
Applied Language of Thought Hypothesis to analyze LLM abstract reasoning on ARC.
EMNLP Findings, 2024
Created MC-LARC benchmark to pinpoint where LLM understanding breaks down.
arXiv preprint, 2025
Discovered emergent cognitive biases in LLM decision-making resembling human gambling addiction.
ICML MI Workshop (Spotlight), 2026
Training-free random embedding injection widens early-token diversity and Pass@N, the inference-time prescription.