Research Philosophy
Core Philosophy
Research Program: Three Questions
My work follows a coherent trajectory through three interconnected questions, each building on the findings of the previous.
Question 1: How Does LLM Reasoning Differ from Human Reasoning?
To characterize this difference, I adopted the Language of Thought Hypothesis (LOTH) from cognitive science, which identifies three essential properties of human reasoning: logical coherence, compositionality, and productivity.

Applying the Language of Thought framework: comparing human reasoning properties (left) with LLM performance on the same dimensions (right)
I applied this framework to evaluate LLM performance on the Abstraction and Reasoning Corpus (ARC), a visual reasoning benchmark designed by Francois Chollet. The results revealed a fundamental brittleness in LLM reasoning: in 57.8% of cases, presenting the same logical rule with a different visual pattern caused the model to treat it as an entirely different problem. Maximum compositional ability — combining multiple transformation functions — reached only 29%.
These findings, published in ACM Transactions on Intelligent Systems and Technology (TIST, 2024), suggest that LLMs rely on pattern matching rather than genuine compositional reasoning.
Question 2: What Do LLMs Understand and What Don’t They?
The first study raised a methodological question: how can we precisely diagnose where model understanding fails? Traditional generation-based evaluation makes errors opaque — when a model produces a wrong answer, the source of failure remains hidden.
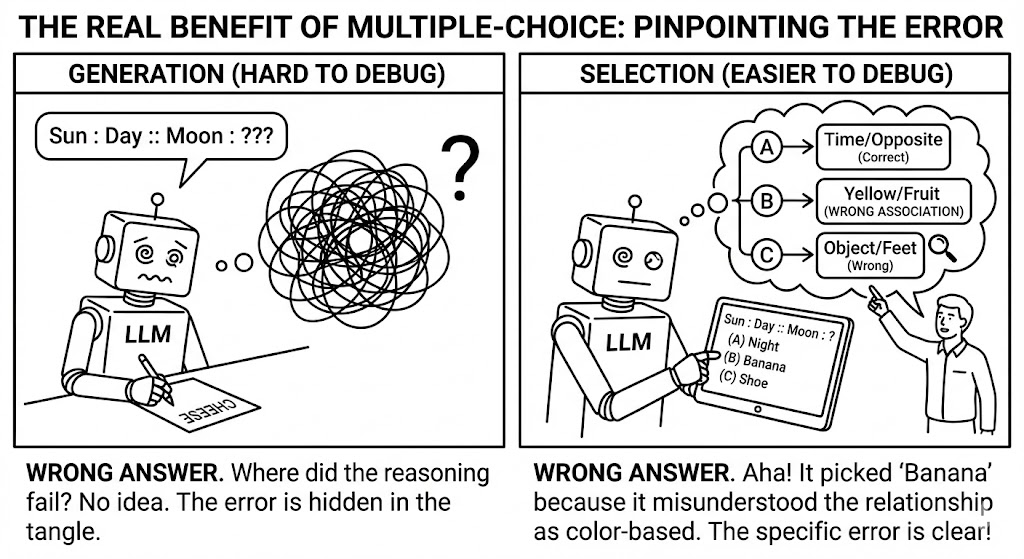
Generation-based evaluation obscures failure modes; selection with contrastive options reveals the specific nature of misunderstanding
To address this, I developed MC-LARC, a benchmark that converts analogical reasoning tasks into a multiple-choice format with contrastive distractors. Each incorrect option is designed to diagnose a specific type of reasoning failure. Results showed a substantial gap between human performance (90%) and the best LLMs (60%), and demonstrated that evaluation format itself determines what we can learn about model capabilities.
This work was published at EMNLP Findings 2024.
Question 3: Why Do AI Systems Exhibit Irrational Behavior?
While the first two questions examined reasoning deficits, an unexpected finding emerged: LLMs can develop behavioral patterns that are not merely suboptimal but irrational in ways that parallel known human cognitive biases.

Investigating whether LLMs develop irrational decision-making patterns analogous to gambling addiction
I investigated whether LLMs can develop patterns resembling gambling addiction, and found that these models exhibit illusion of control, loss chasing, and the gambler’s fallacy as emergent phenomena — not simple imitation of training data. A 20% performance gap between fixed and variable betting conditions suggests these biases are structured and systematic. Mechanistic analysis using Sparse Autoencoders (SAE) confirmed that specific interpretable features activate during irrational decision patterns.
Methodology
Future Directions
My research is evolving from analyzing static reasoning to building adaptive agents, with memory as the bridging concept.
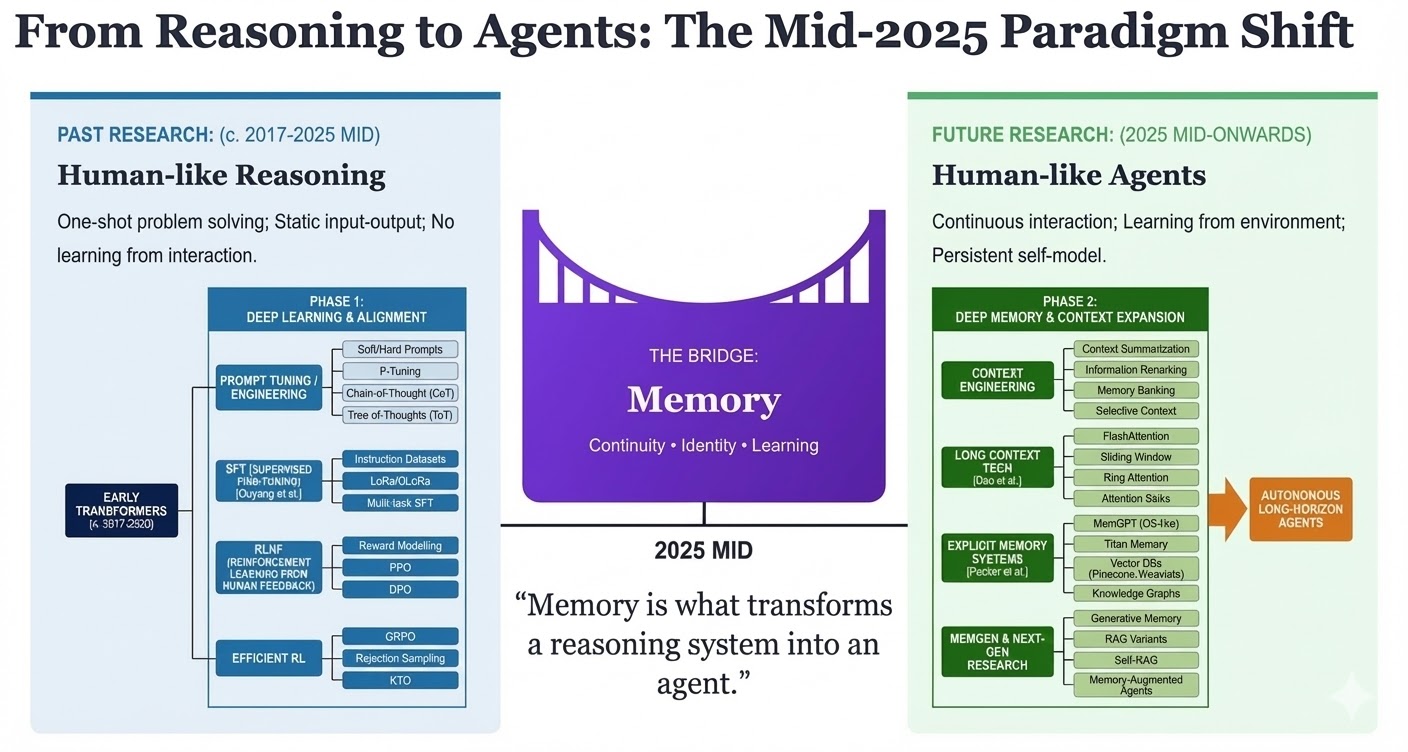
Memory is what transforms a reasoning system into an agent: from static problem-solving to continuous interaction and learning
Human learning derives its power not from single-instance reasoning but from the accumulation and reflection on experience — working memory, episodic memory, and metacognition.

Current AI memory relies on inefficient database retrieval; human memory operates through efficient real-time generation
I am currently developing TTMG (Test-Time Memory Generation), a generative memory framework that dynamically adapts to new problems at test time while keeping the core model parameters frozen. Inspired by how human memory reconstructs — rather than retrieves — stored information to fit the current context, TTMG uses a lightweight Weaver module to generate working, planning, and long-term memory representations in latent space, followed by a Structure Optimizer that refines these representations through gradient ascent on output confidence. Unlike RAG (which depends on retrieval quality and cannot create new patterns) or fine-tuning (which risks catastrophic forgetting), TTMG preserves pretrained capabilities entirely while enabling out-of-distribution adaptation.
The broader goal is to develop agents that improve through interaction: systems that accumulate knowledge, reconstruct relevant experience on the fly, and adapt to unfamiliar situations — ultimately closing the loop between understanding intelligence and building it.
Related Publications
ACM TIST, 2024
Applied Language of Thought Hypothesis to analyze LLM abstract reasoning on ARC.
EMNLP Findings, 2024
Created MC-LARC benchmark to pinpoint where LLM understanding breaks down.
arXiv preprint, 2025
Discovered emergent cognitive biases in LLM decision-making resembling human gambling addiction.